एएससीआईआई (सूचना इंटरचेंज के लिए अमेरिकी मानक कोड) - लैटिन वर्णमाला के मूल पाठ एन्कोडिंग
अंतर्राष्ट्रीय दूरसंचार संघ के अनुसार, मेंकुछ नियमितता के साथ 2016 इंटरनेट साढ़े तीन अरब लोगों का आनंद लिया। उनमें से ज्यादातर भी के बारे में है कि एक पीसी या मोबाइल उपकरणों के माध्यम से उन्हें भेजे गए किसी भी संदेश है, साथ ही ग्रंथों सभी प्रकार के मॉनिटर पर प्रदर्शित किए जाते हैं, वास्तव में, 0 और 1. इस का एक संयोजन जानकारी के इनकोडिंग प्रतिनिधित्व कहा जाता है में नहीं सोचता। यह प्रदान करता है और उसके भंडारण, प्रसंस्करण और पारेषण के कार्यान्वयन की सुविधा। 1963 में, अमेरिका ASCII कोड विकसित किया गया है, जो इस लेख का विषय है।

कंप्यूटर में सूचना की प्रस्तुति
किसी भी इलेक्ट्रॉनिक कंप्यूटिंग के दृष्टिकोण सेमशीन पाठ व्यक्तिगत वर्णों का एक सेट है। इसमें केवल अक्षर शामिल नहीं हैं, जिनमें कैपिटल अक्षर शामिल हैं, लेकिन विराम चिह्न भी हैं, संख्याएं। इसके अतिरिक्त, विशेष प्रतीक "=", "और", "(" और रिक्त स्थान का उपयोग किया जाता है।
पाठ बनाने वाले पात्रों का सेट,को वर्णमाला कहा जाता है, और उनकी संख्या शक्ति है (एन के रूप में चिह्नित)। इसे निर्धारित करने के लिए, अभिव्यक्ति एन = 2 ^ बी का उपयोग करें, जहां बी बिट्स की संख्या या किसी विशिष्ट प्रतीक का वजन है।
यह साबित हुआ है कि 256 वर्णों की क्षमता वाला एक वर्णमाला आपको सभी आवश्यक प्रतीकों का प्रतिनिधित्व करने की अनुमति देता है।
चूंकि 256 दो की आठवीं शक्ति है, इसलिए प्रत्येक प्रतीक का वजन 8 बिट है।
उपाय के 8 बिट की यूनिट एक 1-बाइट कहा जाता है, तो हम कहते हैं कि पाठ जो आपके कंप्यूटर पर संग्रहीत किया जाता है, में किसी भी चरित्र के बाइनरी कोड स्मृति में से एक बाइट पर है।

कोडिंग कैसे किया जाता है
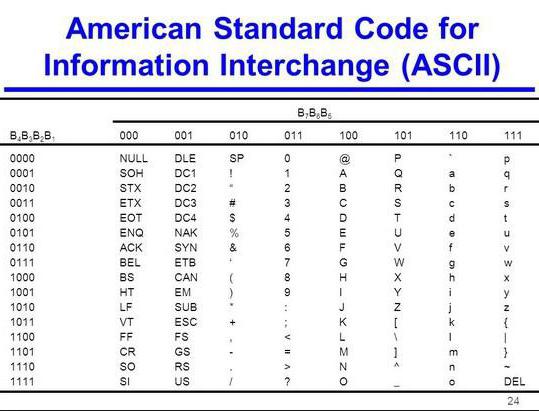
किसी भी ग्रंथ निजी की याद में दर्ज किए गए हैंकुंजीपटल की कुंजी के माध्यम से कंप्यूटर जिस पर नंबर, अक्षर, विराम चिह्न और अन्य प्रतीकों लिखी जाती हैं। रैम में, उन्हें द्विआधारी कोड में प्रेषित किया जाता है, यानी, प्रत्येक वर्ण को प्रथागत मानव दशमलव कोड से मेल किया जाता है, 0 से 255 तक, जो कि बाइनरी कोड से मेल खाता है - 00000000 से 11111111 तक।
बाइट-बाइट चरित्र एन्कोडिंग की अनुमति देता हैप्रोसेसर पाठ की प्रसंस्करण कर रहा है, प्रत्येक प्रतीक को अलग से एक्सेस करें। साथ ही, किसी भी चरित्र की जानकारी का प्रतिनिधित्व करने के लिए 256 वर्ण पर्याप्त हैं।

एएससीआईआई कैरेक्टर एन्कोडिंग
अंग्रेजी में यह संक्षेप सूचना विनिमय के लिए अमेरिकी मानक कोड के लिए है।
कम्प्यूटरीकरण की शुरुआत में, यह स्पष्ट हो गया किआप एन्कोडिंग जानकारी के विभिन्न तरीकों से आ सकते हैं। हालांकि, एक कंप्यूटर से दूसरे कंप्यूटर में जानकारी स्थानांतरित करने के लिए, इसे एक मानक विकसित करना आवश्यक था। इसलिए, अमेरिका में 1 9 63 में एक एएससीआईआई एन्कोडिंग टेबल थी। इसमें, कंप्यूटर वर्णमाला के किसी भी प्रतीक को बाइनरी प्रतिनिधित्व में अपना सीरियल नंबर असाइन किया गया है। प्रारंभ में, एएससीआईआई एन्कोडिंग का उपयोग केवल संयुक्त राज्य अमेरिका में किया जाता था, और फिर पीसी के लिए अंतरराष्ट्रीय मानक बन गया।
टेबल सामग्री
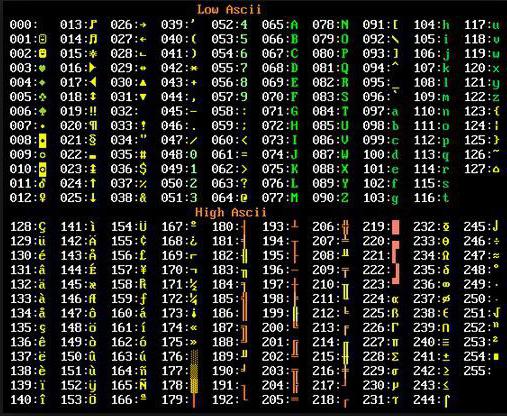
ASCII कोड 2 भागों में विभाजित हैं। अंतरराष्ट्रीय मानक केवल इस तालिका का पहला आधा है। इसमें 0 से क्रमशः संख्याएं (00000000 के रूप में एन्कोडेड) 127 (कोड 01111111) के प्रतीक शामिल हैं।
अनुक्रम संख्या एन | ASCII पाठ एन्कोडिंग | प्रतीक |
0 - 31 | 0000 0000 - 0001 1111 | 0 से 31 तक एन के साथ प्रतीक प्रबंधक कहा जाता है। उनका कार्य एक मॉनीटर या प्रिंटिंग डिवाइस पर टेक्स्ट आउटपुट करने की प्रक्रिया को "गाइड" करना है, एक ऑडियो सिग्नल इत्यादि देना। |
32 - 127 | 0010 0000 - 0111 1111 | 32 से 127 (मानक भाग के साथ एन के साथ प्रतीकटेबल) - लैटिन वर्णमाला के ऊपरी और निचले अक्षरों के अक्षरों, 10 अंक, विराम चिह्न, साथ ही विभिन्न ब्रैकेट, वाणिज्यिक और अन्य प्रतीकों। प्रतीक 32 एक अंतरिक्ष को दर्शाता है। |
128 - 255 | 1000 0000 - 1111 1111 | 128 से 255 (वैकल्पिक भाग से एन के साथ प्रतीकटेबल या कोड पेज) में अलग-अलग प्रकार हो सकते हैं, जिनमें से प्रत्येक का अपना नंबर होता है। कोड पेज का प्रयोग राष्ट्रीय अक्षरों को निर्दिष्ट करने के लिए किया जाता है, जो लैटिन से अलग हैं। विशेष रूप से, यह इसकी मदद से है कि ASCII रूसी अक्षरों के लिए एन्कोड किया गया है। |
एन्कोडिंग तालिका में, अपरकेस और लोअरकेस अक्षरों को वर्णमाला क्रम में एक-दूसरे का पालन करते हैं, और संख्याएं मानों के आरोही क्रम में होती हैं। यह सिद्धांत रूसी वर्णमाला के लिए भी संरक्षित है।
नियंत्रण अक्षर
ASCII एन्कोडिंग तालिका मूल रूप से बनाई गई थीकिसी डिवाइस पर जानकारी प्राप्त करने और प्रसारित करने के लिए जो लंबे समय तक उपयोग नहीं किया गया है, जैसे टेलीलेट। इस संबंध में, इस डिवाइस को नियंत्रित करने के लिए कमांड के रूप में उपयोग किए जाने वाले गैर-प्रिंटिंग को वर्ण सेट में शामिल किया गया था। इसी तरह के आदेशों का इस्तेमाल इस तरह के प्रीकंप्यूटर मैसेजिंग विधियों में मोर्स कोड आदि के रूप में किया गया था।
सबसे आम "teletype" प्रतीक एनयूएल (00, "शून्य") है। यह अभी भी अधिकांश प्रोग्रामिंग भाषाओं में उपयोग किया जाता है, जो अंत-रेखा के चरित्र को दर्शाता है।
जहां ASCII एन्कोडिंग का उपयोग किया जाता है
अमेरिकी मानक कोड की आवश्यकता नहीं हैकुंजीपटल से पाठ जानकारी दर्ज करने के लिए। यह ग्राफिक्स में भी प्रयोग किया जाता है। विशेष रूप से, एएससीआईआई आर्ट मेकर प्रोग्राम में, विभिन्न एक्सटेंशन की छवियां एएससीआईआईआई चरित्र प्रतीकों की एक श्रृंखला का प्रतिनिधित्व करती हैं।
इसी तरह के उत्पाद दो प्रकार में आते हैं: छवियों को पाठ में परिवर्तित करके और "चित्र" को एएससीआईआई ग्राफिक्स में परिवर्तित करके ग्राफिक संपादकों के कार्य को निष्पादित करना। उदाहरण के लिए, एक प्रसिद्ध स्माइली एन्कोडिंग प्रतीक का एक ज्वलंत उदाहरण है।
एक HTML दस्तावेज़ बनाते समय ASCII का भी उपयोग किया जा सकता है। इस मामले में, आप वर्णों का एक निश्चित सेट दर्ज कर सकते हैं, और जब आप पृष्ठ देखते हैं, तो स्क्रीन पर एक प्रतीक दिखाई देता है जो इस कोड से मेल खाता है।
ASCII, बहुभाषी साइटों को बनाने के संकेत है कि एक विशेष राष्ट्रीय टेबल से संबंधित नहीं है, ASCII-कोड द्वारा प्रतिस्थापित के रूप में के लिए आवश्यक है।

कुछ विशेषताएं
ASCII एन्कोडिंग में टेक्स्ट जानकारी को एन्कोड करने के लिए, 7 बिट्स का प्रारंभ में उपयोग किया गया था (एक खाली था), लेकिन आज यह 8-बिट के रूप में काम करता है।
ऊपर और नीचे कॉलम में स्थित अक्षर एक-दूसरे से केवल एक-दूसरे से भिन्न होते हैं। यह सत्यापन की जटिलता को बहुत कम करता है।
माइक्रोसॉफ्ट ऑफिस में ASCII का उपयोग करना
यदि आवश्यक हो तो इस प्रकार का टेक्स्ट एन्कोडिंगसूचना का उपयोग माइक्रोसॉफ्ट के टेक्स्ट एडिटर्स, जैसे नोटपैड और ऑफिस वर्ड में किया जा सकता है। हालांकि, टाइप करते समय, इस मामले में कुछ कार्यों का उपयोग करना असंभव होगा। उदाहरण के लिए, आप बोल्ड में चयन नहीं कर पाएंगे, क्योंकि ASCII एन्कोडिंग केवल सामान्य जानकारी और रूप को अनदेखा कर, जानकारी का अर्थ सुरक्षित रखती है।
मानकीकरण
आईएसओ ने आईएसओ 885 9 मानकों को अपनाया है। यह समूह अलग-अलग भाषा समूहों के लिए आठ-बिट एन्कोडिंग को परिभाषित करता है। विशेष रूप से, आईएसओ 885 9 -1 एएससीआईआई विस्तारित है, जो संयुक्त राज्य अमेरिका और पश्चिमी यूरोप के देशों के लिए एक मेज है। और आईएसओ 885 9-5 रूसी समेत सिरिलिक के लिए उपयोग की जाने वाली एक मेज है।
कई ऐतिहासिक कारणों से, आईएसओ 885 9-5 मानक का बहुत लंबा उपयोग नहीं किया गया था।
इस समय रूसी भाषा के लिए, एन्कोडिंग वास्तव में उपयोग किया जाता है:
- सीपी 866 (कोड पृष्ठ 866) या डॉस, जिसे अक्सर वैकल्पिक कोडिंग गोस्ट कहा जाता है। यह सक्रिय रूप से पिछली शताब्दी के 90 के दशक तक उपयोग किया जाता था। फिलहाल, लगभग इस्तेमाल नहीं किया गया।
- KOI-8। कोडिंग 1 9 70-80 में विकसित की गई थी, औरयह रूनेट में ई-मेल संदेशों के लिए मानक है। यह लिनक्स समेत यूनिक्स परिवार के ओएस में व्यापक रूप से उपयोग किया जाता है। केओआई -8 के "रूसी" संस्करण कोओआई -8 आर कहा जाता है। इसके अलावा, अन्य सिरिलिक भाषाओं के लिए संस्करण हैं, उदाहरण के लिए, यूक्रेनी।
- कोड पृष्ठ 1251 (सीपी 1251, विंडोज़ - 1251)। विंडोज वातावरण में रूसी भाषा के लिए समर्थन प्रदान करने के लिए माइक्रोसॉफ्ट कॉर्पोरेशन द्वारा विकसित किया गया।
पहले मानक सीपी 866 का मुख्य लाभविस्तारित ASCII के समान पदों पर छद्म-ग्राफिक प्रतीकों का संरक्षण था। इसने अपरिवर्तित पाठ कार्यक्रम, विदेशी उत्पादन, जैसे प्रसिद्ध नॉर्टन कमांडर चलाने की अनुमति दी। फिलहाल, सीपी 866 का उपयोग विंडोज के तहत विकसित कार्यक्रमों के लिए किया जाता है जो पूर्ण स्क्रीन पाठ मोड में या एफएआर प्रबंधक समेत टेक्स्ट विंडो में काम करते हैं।
सीपी 866 एन्कोडिंग में लिखे गए कंप्यूटर ग्रंथों में हाल ही में दुर्लभ रहा है, लेकिन इसका उपयोग "विन्डस" में रूसी फ़ाइल नामों के लिए किया जाता है।
"यूनिकोड"
फिलहाल, सबसे व्यापकइस विशेष एन्कोडिंग प्राप्त किया। यूनिकोड कोड क्षेत्रों में विभाजित हैं। पहला (यू +0000 से यू +007 एफ तक) कोड के साथ ASCII सेट के पात्र शामिल हैं। फिर विभिन्न राष्ट्रीय स्क्रिप्ट के संकेतों के साथ-साथ विराम चिह्न और तकनीकी प्रतीकों के क्षेत्रों का पालन करें। इसके अलावा, भविष्य में नए प्रतीकों को शामिल करने की आवश्यकता होने पर यूनिकोड कोड का हिस्सा आरक्षित है।

अब आप जानते हैं कि ASCII एन्कोडिंग में, प्रत्येकप्रतीक 8 शून्य और एक के संयोजन के रूप में दर्शाया गया है। गैर-विशेषज्ञों के लिए, यह जानकारी अनावश्यक और अनिच्छुक प्रतीत हो सकती है, लेकिन क्या आप नहीं जानना चाहते कि आपके पीसी के "दिमाग" में क्या हो रहा है?
</ p>



